
It’s been a while since my last update on my work on assisted well log interpretation through machine learning. The good news is that I have been quite busy on the topic in the meantime. In fact, I have been collaborating with Equinor, which is Norway’s biggest oil and gas company as well as an industry partner in my research group CIUS. This collaboration led to a tool for assisted well log interpretation that is now in active use by Equinor’s cased hole logging group. More on that below!
In our initial project on the topic, described here, we trained convolutional neural networks to interpret well integrity logs. The training process provided the networks with log data and corresponding expert interpretations. Thus, the network could train itself to produce reasonable interpretations of new log data.
While performance was quite good, we saw that it was hampered by a few issues. The primary issue was the subjectivity inherent in the interpretations that we used for training and testing. With an annotation scheme that is essentially an opinion-based scale from “Good” to “Poor”, it is difficult for a team of interpreters to stay consistent. Such inconsistencies can easily trip up machine learning, as I discussed in my earlier post. This is called overfitting, and essentially means that the machine learning gets the wrong idea from its training examples. In our specific case, overfitting means that it misunderstands how an aspect of log data should lead to a particular interpretation.

Second article
After our first publication, we worked on improving performance by helping the machine learning to not get as confused by inconsistent interpretations. We published our results in a second article, first in the proceedings of a conference, and then in SPE Journal.
Feature engineering
In the first article, we directly provided the machine learning with log data. This data contains quite a bit of junk that human interpreters learn to look past. In addition, there’s a lot of information in the image data that is not directly relevant for interpretation. This junk data and extraneous data may confuse the machine learning, especially in combination with inconsistent interpretations. It doesn’t really know what it’s looking at, and has no way to make sense of it except through its learning examples.
On the other hand, humans intuitively know how to break down this information. To help deal with these issues, we used our domain knowledge to perform feature engineering. This means that we specified how to draw a set of features from the log data, features that we know to be predictive.
Experimenting with different classifiers

We also moved from complex convolutional neural networks to other kinds of classifiers, some of them a lot simpler. The idea is that complex classifiers have a lot of learning capacity. They can use this to solve more complex tasks — but also to learn to overfit. Simpler classifiers may be able to compensate for their lack of cleverness by being more robust to overfitting. Some are even designed for robustness. In the second article, we compared the performance of many different classifiers in the scikit-learn library on this task.
Performance
These improvements meant that we could squeeze out some more performance on the task. The accuracy improvement corresponds to making about 10–20% fewer misclassifications, depending on how you count. However, we still saw that the performance was still limited due to subjectivity in the annotations used for training. Which brings us to the next project!
Collaboration with Equinor
From February 2021 to April 2022, I had a 50% position working with Equinor, Norway’s biggest oil and gas company. We built a prototype assisted well log interpretation tool that would do the job that we had envisioned all along: Take a well integrity log, and quickly and automatically produce an interpretation that a human expert could use as a basis for their own interpretation.
In my previous work, I had been working only with other researchers. Now, I would collaborate with well integrity log interpretation experts, who would also be among the end users. One major advantage of this collaboration is that these experts could help build a thoroughly quality controlled dataset of well logs for training and testing. But there were more advantages as well:
Better annotation scheme
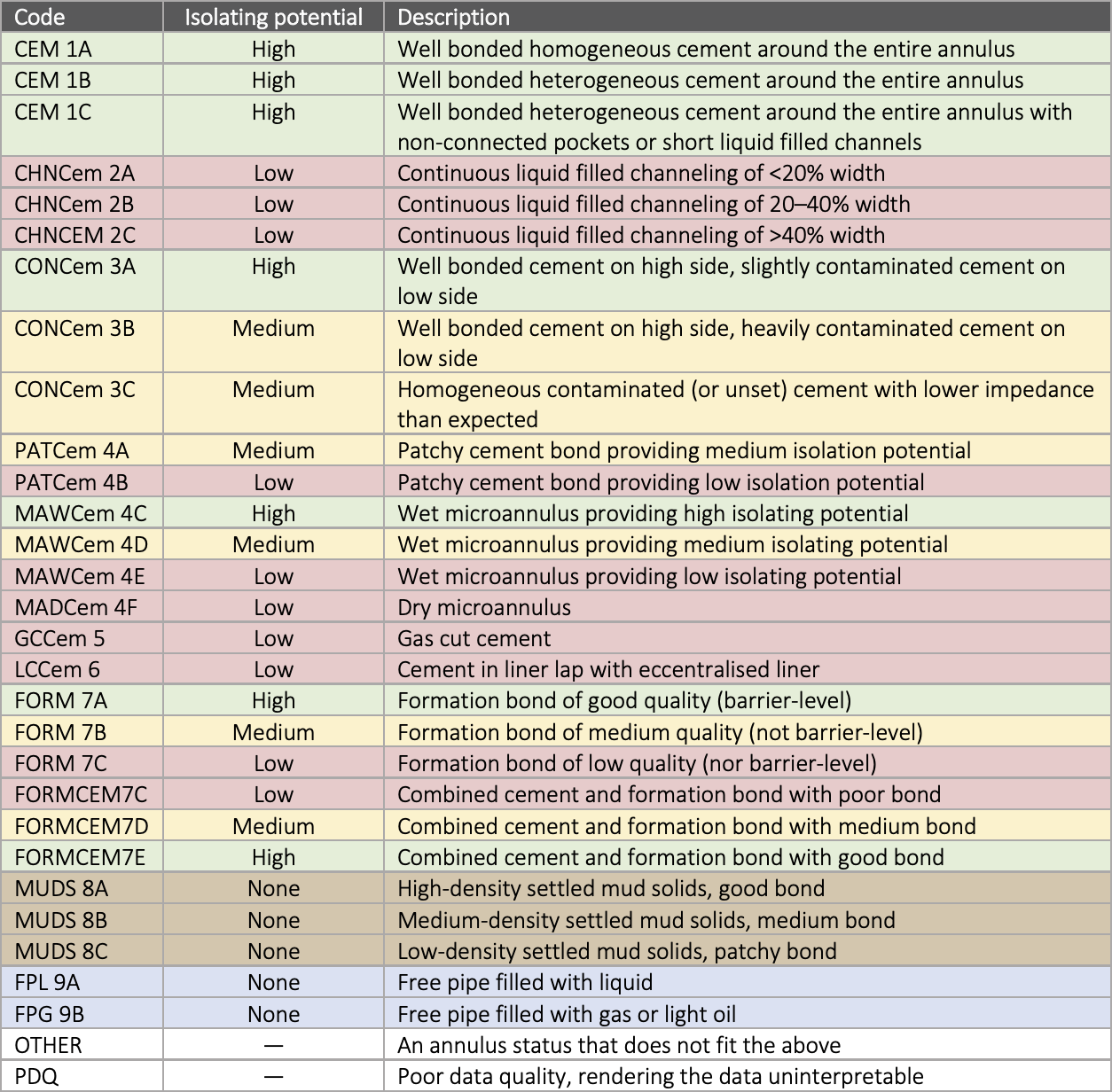
In my previous work, I had worked on an older dataset of well logs from Equinor, recorded from 2009 to 2013. These were interpreted using an older interpretation scheme. As I said above, this scheme was opinion-based and hence subjective by nature. Now, however, we could use newer logs, interpreted according to Equinor’s new scheme, shown to the right. The 30 different classes of this scheme are different descriptions of exactly what is outside the casing. For example:
- The CEM 1A class represents well bonded homogeneous cement around the entire annulus,
- CHNCem 2B represents a liquid filled channel covering 20–40% of the casing circumference, and
- FPL 9A represents a liquid filled free pipe.
This new scheme allows interpreters to make a more precise and objective interpretation. In my opinion, it is a massive improvement over the old scheme. However, there is still obviously some room for subjectivity. Some classes still have an unclear boundary — for example, when exactly do we go from well bonded homogeneous cement (CEM 1A) to well bonded heterogeneous cement (CEM 1B)? The level of interpretation detail can also vary between interpreters; one may define an interval as a long zone of one class such as CEM 1C where another may split the interval into smaller zones of different classes. (The latter issue also existed with the older interpretation scheme, of course.)
Technical improvements to the machine learning
We also performed various improvements to the machine learning. First, we used our domain knowledge to remove as much of the aforementioned junk data as we could. In particular, this junk data occurred at well depths with casing collars or casing centralisers, which cause visible spikes in the data. By identifying these spikes and removing data at those depths, we were able to calculate features based on cleaner data.
In addition, we defined some new and useful features. To a large degree, we were inspired by looking at the different classes in the interpretation scheme and thinking of what information the machine learning would need to distinguish these classes. For example, impedance differences between the top and bottom of the casing help to distinguish liquid channels through solids, which almost always appear at the bottom. The probability of being below the top of cement helps to distinguish formation collapse from cement. (We estimated this probability from our log dataset and its theoretical top of cement values.) A feature specifying whether or not there is another casing outside the annulus helps identify liner laps with eccentered liners and exclude formation interpretations in such intervals.
We made more improvements as well. For example, we calculate features both on short and long well log data intervals, to give the machine learning both finely resolved and longer-range information to base its decisions on. We also included a post-processing component to merge or replace very short zones.
Implementation
We wrote the main assisted cement log interpretation codebase as a standalone Python library. For easy use, we scripted a user interface for it into the log interpretation software already used by Equinor’s cased hole logging group. After typing in information in a few text fields and a few mouse clicks, users get an automatic interpretation of the log after a few seconds.
At some point in the near future, we will share the codebase as open-source software as well. This will let you see exactly what we did and how we did it!
Results
We published a conference article on this project as part of the SPE Norway Subsurface Conference in April 2022. In short, we saw excellent performance compared to what we had seen before. In theory, the current classification problem, which uses a whopping 28 classes (we exclude OTHER and PDQ from the original 30), should be much more difficult than when using only 6 classes previously. Despite that, we actually saw a higher accuracy than before. The tool chose exactly the same class as the human interpreters 64% of the time, up from 57% in the second article.
UPDATE: In November 2022, we published an expanded and improved version of the article in the journal SPE Drilling & Completion. I strongly recommend reading this version over the conference article!
What’s next?
My involvement in the development of Equinor’s assisted well log interpretation tool is now, for the most part, over. However, when Equinor open-sources the interpretation library, their ongoing improvements to it will become public as well.
For my own part, my focus has now moved onto new projects, which I will probably post about soon!
The header image was composited by myself, using the image of a robot from the excellent The Talos Principle via a screenshot published by Playstation Europe.